All you need is PostgreSQL by Eduardo Bellani
Introduction
There is a deep cultural reflex in modern engineering: whenever a problem appears, reach for a packaged solution instead of thinking from first principles. The result is architectural cargo culting and lots of missed opportunities. Some intentionally absurd-but-familiar examples:
We need an audit trail, let’s use {temporal/event sourcing DBMS}
Our application is slow, let’s cache that using {in-memory key-value database}
And since a relational database like PostgreSQL is still considered mandatory,thanks mostly to its unmatched reputation, companies end up stacking product on top of product on top of PostgreSQL. They inflate the number of moving parts, operational risk, headcount demand, and overall system entropy. Complexity1 grows, not because the problems demand it, but because someone reached for a tool they saw in a conference talk.
In this post, I’ll walk through a set of common misconceptions that drive teams to introduce new infrastructure when they don’t need to. All of these can be solved with vanilla PostgreSQL 18 using standard extensions available on RDS, with no special infrastructure and no distributed-systems cosplay.
The goal in this article is not to argue that specialized systems are never appropriate, but to show that the default assumption for your data problems should be that my company can do fine with just PostgreSQL.
The setup
Here is a list of arguments that people put forth to reach for other tools besides PostgreSQL, based on my experience:
- I’ll need auditing and reconstructing state
- Write throughput is too low
- The transactional queries are too slow
- The analytical queries are too slow
- My app will be coupled to the Database
To address these, I’m going to use a variation of the Drosophila melanogaster of the database field: the classic Supplier and Parts database(Date 2003). I’ll update it to be more in line with the usual problematic tables: Financial Transaction and their originating transfers.
For the rest of this article we will be constructing a database design based on modern PostgreSQL that will achieve the general goals listed above and specific business requirements. Here is a requirements snippet from a very popular banking API company:
Transactions: are immutable records of financial interactions with Increase. You can think of them as the line items on your bank statement. A Transaction with a positive amount means there’s more money in your account. A Transaction with a negative amount means there’s less money in your account. You can’t directly create a Transaction, and they never change after they are made. Anything that causes money to move around your Increase account results in a Transaction - initiated or received transfers, card payments, earned interest, and more.
Transfers: which includes ACH Transfers, Wire Transfers, etc - are the most common way to initiate money movement over external networks with Increase. Transfers are one-to-many with Transactions, which they create as side-effects. Unlike Transactions, Transfers are stateful and transition through a lifecycle of different statuses as they move across the network.
Pending Transactions: represent potential future credits or debits of money into your account and are a separate resource from Transactions (despite their similar name). Notably, while Transactions are immutable, Pending Transactions are not, as they don’t guarantee the movement of money. For example, Pending Transactions are created for card authorizations (which can mutate or timeout) and also when placing a hold on an account (which can be removed). Pending Transactions do not affect your current balance (which is the balance you earn interest on), but do affect your available balance (which is the amount you’re able to move out of Increase). (Increase, Inc. 2025)
Below are 2 screenshots from increase’s sandbox dashboard that showcase the requirements:
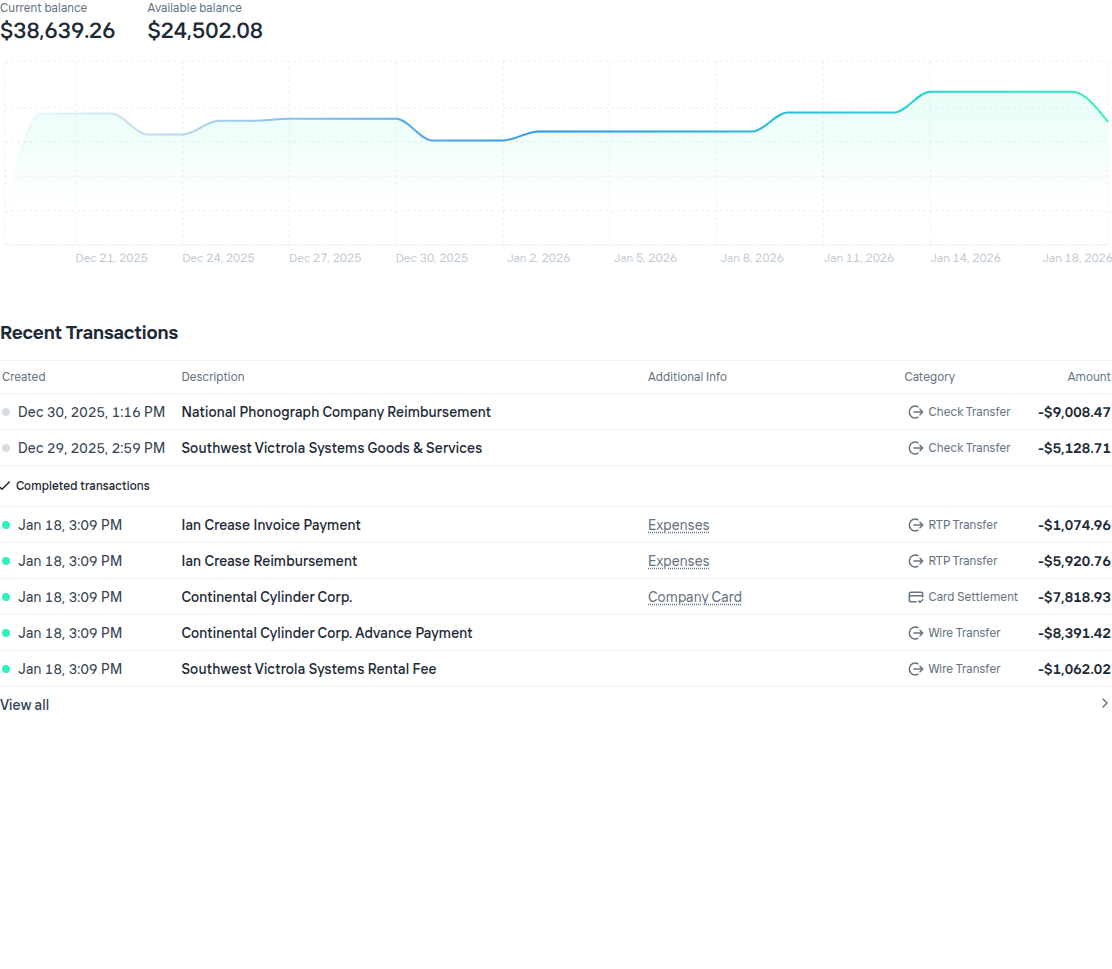
Figure 1: Increase account dashboard
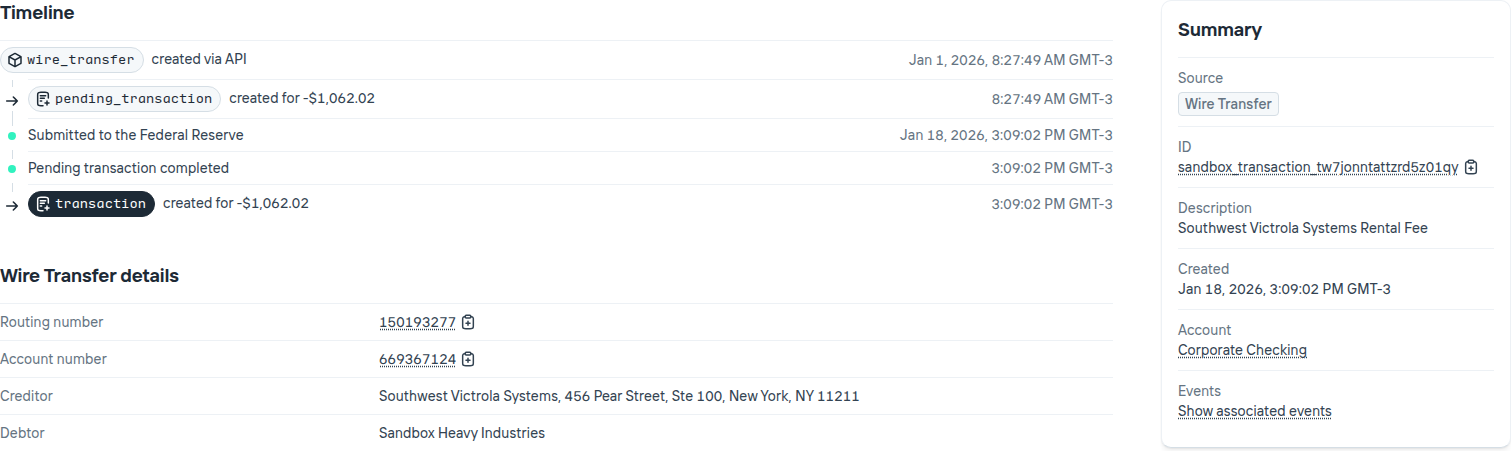
Figure 2: Increase details
From these 2 images, here is a list of requirements (functional and not) that I have extracted, which I consider to be common in financial systems like increase:
- Accounts are defined by immutable routing numbers and account numbers and have a status that can vary.
- Accounts are discriminated between external and managed, and one account must be one or the other exclusively. Transfers are made only between external and managed accounts.
- Transactions and transfers are listed, paginated by their respective creation times.
- Current and available balance are shown, both their present and historical daily values
- Transfers behave like a state machine where the progression between states are exposed to the user. The user can see the full state history of a transfer and some of these states are linked to pending/settled transactions.
- The user can also see the details of a transaction, and see the transfer that generated it.
- We should maximize write throughput of transactions and transfers. Transfers are editable, and so we should be able to update them fast too.
Laying the foundation
In this section we build the core tables2 and the role necessary to restraint updates and achieve the immutability mentioned on the requirements (requirement 1 for example).
The foundation: schemas and user roles for modularity
Modularity, defined by the capacity to have a many-to-many relation between implementations and interfaces(Koppel 2023), is crucial for software development(Yourdon and Constantine 1979). Part of the base tools we have for that on SQL are schemas and roles. In particular, a proper role3 can be used for defining very precise interfaces on top of database objects(Swart 2019).
create schema finance;
create role finance;
grant usage on schema finance to finance;
alter default privileges in schema finance
grant select, insert, update, delete on tables to finance;
alter default privileges in schema finance
grant usage, select on sequences to finance;
Domains
Database domains are usually scoffed at by practitioners, but that is a big mistake. Properly seen, they are
an application of the abstract data type to database management. (Pascal 2019)
As such, domains are the core building blocks for logical design.
create domain finance.routing_number as text
check (value ~ '^[0-9]{9}$');
create domain finance.account_number as text
check (value ~ '^[0-9]{12}$');
create domain finance.transfer_status as text
check(value in ('pending',
'returned',
'completed'));
The transfer_status in particular is crucial, since it represents the
valid states that a state machine can have.
Accounts, managed and external
Managed Accounts are the accounts that are owned by the our system. When receiving a transfer, we control only one side of the transfer, and that is the managed account side.
Managed accounts can be deactivated and reactivated. This falls neatly within the set of temporal features introduced in SQL 2011(Kulkarni and Michels 2012), in particular application time, recently introduced in PostgreSQL 18(PostgreSQL Wiki Contributors 2024). This feature allows us to represent accounts going in and out of activity without overlapping.4
-- To use temporal constraints, you need to install the btree_gist extension, which provides the necessary operator classes for creating GiST indexes on scalar data types:
create extension if not exists btree_gist;
create table finance.managed_active_account(
routing_number finance.routing_number not null,
account_number finance.account_number not null,
account_name text not null,
account_active_period tstzrange not null default tstzrange(now(), 'infinity', '[)'),
primary key (routing_number,
account_number,
account_active_period without overlaps)
);
comment on table finance.managed_active_account is
'Managed Accounts are what transactions are performed against. Think of your bank account. They store money, receive transfers, and send payments. They earn interest and have depository insurance. This relation holds the accounts that are active. No transfer may be created for accounts in the period that they were inactive.';
create table finance.external_account(
routing_number finance.routing_number not null,
account_number finance.account_number not null,
account_name text not null,
primary key (routing_number, account_number)
);
comment on table finance.external_account is
'External accounts represent counterparty accounts at other institutions. They are the other side of a transfer. Unlike managed accounts, they have no temporal active period since we do not control their lifecycle.';
And below we finish the accounts by making sure a managed account and an
external account can’t be the same. We need to use alter table instead
of adding these check constraints on the table definitions because of
the circular dependency (one table depends on the other, and vice
versa).
-- Ensure managed and external accounts never share the same identity
create or replace function finance.not_external_account(
p_routing_number finance.routing_number,
p_account_number finance.account_number
)
returns boolean language sql stable as $$
select not exists (
select 1
from finance.external_account
where routing_number = p_routing_number
and account_number = p_account_number
);
$$;
create or replace function finance.not_managed_account(
p_routing_number finance.routing_number,
p_account_number finance.account_number
)
returns boolean language sql stable as $$
select not exists (
select 1
from finance.managed_active_account
where routing_number = p_routing_number
and account_number = p_account_number
);
$$;
alter table finance.managed_active_account
add constraint managed_not_external
check (finance.not_external_account(routing_number, account_number));
alter table finance.external_account
add constraint external_not_managed
check (finance.not_managed_account(routing_number, account_number));
Transfers, constrained by a state machine and temporal periods
Below are the transfers, which represents the movement of money between
managed accounts and external accounts. They can be seen as a state
machine progressing over the transfer_status domain pending -> (completed | returned).
Another crucial point here is the period keyword in the references
section. This makes a transfer period be consistent with active managed
accounts, implementing a core financial safety requirement declaratively
in the most deepest level one can.
create table finance.transfer (
transfer_period tstzrange not null default tstzrange(now(), 'infinity', '[)'),
transfer_created_at timestamptz
generated always as (lower(transfer_period)) stored,
account_number finance.account_number not null,
routing_number finance.routing_number not null,
counterparty_account_number finance.account_number not null,
counterparty_routing_number finance.routing_number not null,
amount bigint not null,
status finance.transfer_status not null default 'pending',
-- Natural order: account identity, then time, then counterparty
-- This enables efficient time-range queries on account transfers
primary key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
),
foreign key (
counterparty_routing_number,
counterparty_account_number
) references finance.external_account (
routing_number,
account_number
),
-- temporal foreign key: ensure managed account exists during transfer period
foreign key (
routing_number,
account_number,
period transfer_period
) references finance.managed_active_account (
routing_number,
account_number,
period account_active_period
)
);
comment on table finance.transfer is
'Transfers represent money movement between an external account and a managed account. Status follows state machine: pending -> (completed | returned). Period closes on terminal state. transfer_created_at is a stored generated column derived from lower(transfer_period), eliminating redundancy while remaining usable in primary keys and foreign key references.';
revoke insert on finance.transfer from finance;
revoke update on finance.transfer from finance;
-- transfer_period will be managed based on the status
grant insert (routing_number,
account_number,
counterparty_routing_number,
counterparty_account_number,
amount) on finance.transfer to finance;
grant update (status) on finance.transfer to finance;
Note that transfer_created_at is a stored generated column:
lower(transfer_period) is an immutable function, and the lower bound
of transfer_period never changes (the state machine trigger only
closes the upper bound). This eliminates the redundancy between
transfer_created_at and lower(transfer_period) while keeping the
column usable in primary keys and as a foreign key target.
Transfer state history
In order to implement feature 5, we need system-time temporal tables5. PostgreSQL supports several approaches for temporal tables. For simplicity and portability (including RDS), we use the temporal_tables extension (https://nearform.com, n.d.).
The extension automatically writes old versions of each row to a history
table on every UPDATE or DELETE. Together with a tstzrange period,
this gives you a full history suitable for AS OF queries and state
reconstruction. We create a focused history table that only tracks what
we need: the transfer identity, status, and system-time period.
-- Add system-time period column to transfer table
alter table finance.transfer add column if not exists sys_period tstzrange default tstzrange(current_timestamp, null);
alter table finance.transfer alter column sys_period set not null;
-- Focused history table - only what we need for status transitions
create table if not exists finance.transfer_status_log (
like finance.transfer
);
comment on table finance.transfer_status_log is
'Automatic log of all transfer status transitions via temporal_tables extension. Shows complete state machine history.';
alter table finance.transfer_status_log
add primary key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number,
sys_period
);
-- Use temporal_tables versioning procedure
create trigger transfer_save_status_history
before insert or update or delete
on finance.transfer
for each row
execute procedure versioning('sys_period', 'finance.transfer_status_log', true);
Once applied, finance.transfer_status_log will contain every past version
of every transfer’s status, from which you can reconstruct the state machine
history over time.6
Account auditing
Since we are on the subject of temporal tables, we might as well add support for auditing accounts. It lies outside our list of features, but I think account disabling is a major event that should have strong auditing behind it, so we might as well add it.
-- Add system-time period column to the account table
alter table finance.managed_active_account add column if not exists sys_period tstzrange default tstzrange(current_timestamp, null);
alter table finance.managed_active_account alter column sys_period set not null;
create table if not exists finance.managed_active_account_log (
like finance.managed_active_account
);
comment on table finance.managed_active_account_log is
'Automatic log of all account activity via temporal_tables extension.';
create index on finance.managed_active_account_log (sys_period);
create index on finance.managed_active_account_log (routing_number, account_number);
-- Use temporal_tables versioning procedure
create trigger account_save_history
before insert or update or delete
on finance.managed_active_account
for each row
execute procedure versioning('sys_period', 'finance.managed_active_account_log', true);
Transactions, the immutable events
Contrasted with the above, below we have transactions, which represent changes in the balances (current and available) of an account and are therefore immutable.
Transactions reference their originating transfer by identity (the
transfer’s natural key including transfer_created_at), not by
period. There is no transfer_period stored on transactions — the
transfer’s temporal state is queried from the transfer table when
needed.
create table finance.settled_transaction (
transaction_created_at timestamptz not null default now(),
account_number finance.account_number not null,
routing_number finance.routing_number not null,
counterparty_account_number finance.account_number not null,
counterparty_routing_number finance.routing_number not null,
transfer_created_at timestamptz not null,
amount bigint not null,
primary key (
account_number,
routing_number,
transaction_created_at
),
foreign key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
references finance.transfer (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
);
comment on table finance.settled_transaction is
'Settled transactions affect both your available balance and your current balance. They are immutable events --- no updates or deletes permitted.';
revoke update, delete on finance.settled_transaction from finance;
create table finance.pending_transaction (
like finance.settled_transaction including all,
foreign key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
references finance.transfer (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
);
comment on table finance.pending_transaction is
'Pending transactions represent potential future credits or debits. They affect available balance but not current balance. Immutable once created.';
revoke update, delete on finance.pending_transaction from finance;
On maintaining business rules via meaningful constraints
Constraints should really be part of the foundation, but I have made them a separate section because they are usually seen as something apart from defining tables. In reality, a proper mathematical relation should embrace both intentionality (constraints) and extensionality (rows).
It is impossible to design and interrogate a database sensibly, and ensure semantic consistency of results … it is intended to represent without … DBMS knowledge of the meaning assigned to the database…(Pascal 2026)
In our case, several business rules must hold across tables. In the
absence of SQL’s assert7 we rely on constraint triggers keeping
them as declarative as possible.
The transfer state machine
create or replace function finance.enforce_transfer_state_machine()
returns trigger language plpgsql as $$
begin
if OLD.status = NEW.status then
return NEW;
end if;
if OLD.status = 'pending' then
if NEW.status not in ('completed', 'returned') then
raise exception 'Invalid state transition: pending can only transition to completed or returned, not %', NEW.status;
end if;
NEW.transfer_period := tstzrange(lower(OLD.transfer_period), now(), '[]');
elsif OLD.status in ('completed', 'returned') then
raise exception 'Invalid state transition: % is a terminal state and cannot transition to %', OLD.status, NEW.status;
end if;
return NEW;
end;
$$;
create trigger transfer_z_enforce_state_machine
before update of status on finance.transfer
for each row
when (OLD.status <> NEW.status)
execute function finance.enforce_transfer_state_machine();
Transactions must fall within the transfer period
A transaction’s transaction_created_at must fall within the
originating transfer’s transfer_period. This prevents creating
transactions against transfers that haven’t started yet or have already
closed:
create or replace function finance.transaction_within_transfer_period()
returns trigger language plpgsql as $$
declare
v_transfer_period tstzrange;
begin
select transfer_period into v_transfer_period
from finance.transfer
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number;
if not found then
raise exception 'Transfer not found for transaction';
end if;
if not (v_transfer_period @> NEW.transaction_created_at) then
raise exception
'Transaction created_at % is outside transfer period %',
NEW.transaction_created_at, v_transfer_period;
end if;
return NEW;
end;
$$;
create constraint trigger settled_transaction_within_transfer_period
after insert on finance.settled_transaction
deferrable initially deferred
for each row
execute function finance.transaction_within_transfer_period();
create constraint trigger pending_transaction_within_transfer_period
after insert on finance.pending_transaction
deferrable initially deferred
for each row
execute function finance.transaction_within_transfer_period();
Pending transactions require a pending transfer
A pending transaction can only be created against a transfer that is
still in the pending state. Settled transactions, conversely, can only
be created against transfers that have left the pending state
(i.e. completed or returned):
create or replace function finance.is_pending_transfer(
p_routing_number finance.routing_number,
p_account_number finance.account_number,
p_transfer_created_at timestamptz,
p_counterparty_routing_number finance.routing_number,
p_counterparty_account_number finance.account_number
)
returns boolean language sql stable as $$
select exists (
select 1
from finance.transfer t
where t.routing_number = p_routing_number
and t.account_number = p_account_number
and t.transfer_created_at = p_transfer_created_at
and t.counterparty_routing_number = p_counterparty_routing_number
and t.counterparty_account_number = p_counterparty_account_number
and t.status = 'pending'
);
$$;
create or replace function finance.ensure_pending_transfer()
returns trigger language plpgsql as $$
begin
if not finance.is_pending_transfer(
NEW.routing_number,
NEW.account_number,
NEW.transfer_created_at,
NEW.counterparty_routing_number,
NEW.counterparty_account_number
) then
raise exception
'Must reference a pending transfer (%, %, %, %, %)',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at,
NEW.counterparty_routing_number, NEW.counterparty_account_number;
end if;
return NEW;
end;
$$;
create or replace function finance.ensure_non_pending_transfer()
returns trigger language plpgsql as $$
begin
if finance.is_pending_transfer(
NEW.routing_number,
NEW.account_number,
NEW.transfer_created_at,
NEW.counterparty_routing_number,
NEW.counterparty_account_number
) then
raise exception
'Cannot reference a pending transfer (%, %, %, %, %)',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at,
NEW.counterparty_routing_number, NEW.counterparty_account_number;
end if;
return NEW;
end;
$$;
create constraint trigger pending_transaction_requires_pending_transfer
after insert on finance.pending_transaction
deferrable initially deferred
for each row
execute function finance.ensure_pending_transfer();
create constraint trigger settled_transaction_requires_non_pending_transfer
after insert on finance.settled_transaction
deferrable initially deferred
for each row
execute function finance.ensure_non_pending_transfer();
No future transactions when closing a transfer
A transfer cannot transition to completed or returned if any of its
transactions have a transaction_created_at that falls after the
moment of closure. This prevents the state machine from closing a
transfer’s period and stranding transactions in the future:
create or replace function finance.no_future_transactions_on_close()
returns trigger language plpgsql as $$
begin
if exists (
select 1 from finance.settled_transaction
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number
and transaction_created_at > now()
union all
select 1 from finance.pending_transaction
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number
and transaction_created_at > now()
) then
raise exception
'Cannot close transfer (%, %, %): transaction(s) exist after current time',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at;
end if;
return NEW;
end;
$$;
create constraint trigger transfer_no_future_transactions_on_close
after update of status on finance.transfer
deferrable initially deferred
for each row
when (NEW.status in ('completed', 'returned'))
execute function finance.no_future_transactions_on_close();
These three constraint groups — temporal containment, status matching, and future-transaction prevention — together enforce the full lifecycle invariant: transactions can only exist within the temporal and logical boundaries of their originating transfer. In application code, this would typically require a coordination framework spanning multiple services. Here it is enforced declaratively at the deepest possible level.
On capacity planning
In order to be able to efficiently modify transfers and run the constraints needed to keep transactions consistent with the business rules we should keep in the working set 2 days of transfers/transactions. The number 2 is chosen because wire transfers typically settle within one business day and while international transfers take one to five days, with most completing within two(Paystand 2024) we.
Taking finance.transfer as a reference (the widest row), we estimate
the per-row size (ignoring alignment(Thomas 2018)):
| Name | Type | Size (bytes) |
|---|---|---|
| transfer_period | tstzrange | 32 |
| transfer_created_at | timestamptz | 8 |
| account_number | text(12) | 13 |
| routing_number | text(9) | 10 |
| counterparty_account_number | text(12) | 13 |
| counterparty_routing_number | text(9) | 10 |
| amount | bigint | 8 |
| status | text(10) | 11 |
| sys_period | tstzrange | 32 |
| Total (plus 24 row header) | 161 |
So roughly 160 bytes per row. The log tables have the same width. The
transaction tables are slightly narrower (no transfer_period, no
status), around 120 bytes per row.
Working set estimation
The working set is the data that must be in shared_buffers for the
system to perform well. As stated above, the working set will consist of
2 days of transfers transactions.
Let’s assume that a transfer row corresponds to 2 rows in
transfer_status_log (the initial insert plus a state change) and 3
transactions (2 pending transactions and a settled transaction). That
gives us 3 transfer like rows + 3 transaction rows.
Each index entry carries 8 bytes of overhead plus the indexed data[cite:@StackOverflowAlbe2020indexsize]. In our design, most tables have one index: the B-tree backing the primary key (the temporal table has 2, but lets ignore that for the sake of simplicity). The primary key for ~finance.transfer indexes 5 columns totalling ~54 bytes, so each
index entry is ~62 bytes. This amounts to roughly 40% of the row
size. So, a safe rule of thumb: add a 1.4 multiplier to the table sizes
to account for for index overhead.
This whole argument boils down to the byte sum of:
((3 * 160) + (3 * 120)) * 1.4
1176.
| Scale | Transfers/day | Working set size for 2 days |
|---|---|---|
| Startup | 10,000 | 22M |
| Mid/large bank(Nubank 2022) | 50,000,000 | 110G |
| Global processor(Inc. 2025) | 900,000,000 | 1.9T |
Up to a mid level bank one can fit the working set comfortably in modern cloud database servers. AWS RDS, for instance, supports up to 4TiB of memory per instance for PostgreSQL-compatible instances(Amazon Web Services 2026).
On write throughput
If you want to maintain semantic enforcement of your data (which in our
model is done via fkeys and constraint triggers) about the best thing
you can do to optimize write throughput is to lower the write
amplification, specifically to use indexes in a smart way. After all,
indexes, if not carefully chosen, can kill performance in a write-heavy application(Gerogiannakis 2019)
Enabling HOT Updates for Transfers
By keeping the primary key of the finance.transfer table aligned with
the immutable columns, we enable Heap-Only Tuple
(HOT)(The PostgreSQL Global Development Group 2025) updates for that table. Such HOT
updates are important because status transitions (pending to
completed/returned) are common operations and we want to minimize write
amplification.
What happens is that, because neither the transfer’s status nor its
transfer_period participate in any indexes, PostgreSQL can write the
new tuple version to the same page (if space permits) and also skip the
index update entirely.
We therefore need to make sure there is enough page space in the table:
alter table finance.transfer set (fillfactor = 70);
This reserves 30% free space per page, allowing updated tuples to fit on
the same page. Combined with no indexes on status or transfer_period,
status updates become HOT-eligible, providing:
- 2-3x faster updates compared to non-HOT updates(Samuel 2024)
- No table and index bloat from status changes(van Veen & Dave Pitts 2022)
- Simpler vacuum maintenance on the table(van Veen & Dave Pitts 2022)
- Smaller WAL, since there is less write activity overall(van Veen & Dave Pitts 2022)
Making sure there are no Unused indexes
A common problem is to have a bunch of unused indexes for critical tables, since they are not visible directly and experiments can be forgotten. So, make sure all indexes are being used (see (Gerogiannakis 2019)(Group, n.d.) for a solution based on PostgreSQL internal statistics):
SELECT schemaname, relname, indexrelname, idx_scan, idx_tup_read, idx_tup_fetch FROM pg_stat_user_indexes where schemaname='finance' ORDER BY idx_scan;
schemaname │ relname │ indexrelname │ idx_scan │ idx_tup_read │ idx_tup_fetch
════════════╪══════════════════════════╪═════════════════════════════════════════╪══════════╪══════════════╪═══════════════
finance │ settled_transaction │ settled_transaction_pkey │ 0 │ 0 │ 0
finance │ transfer_status_log │ transfer_status_log_sys_period_idx │ 0 │ 0 │ 0
finance │ account │ account_pkey │ 100 │ 80 │ 60
finance │ pending_transaction │ pending_transaction_pkey │ 1220000 │ 120000 │ 120000
finance │ transfer │ transfer_pkey │ 2210002 │ 1110002 │ 1110000
- idx_scan
- How many times the index has been scanned (used). This can
be either directly by a application query e.g.
select * from finance.transfer where (transfer_created_at, transaction_account, counterparty_account) = ('2025-11-25 18:04:26.298329+00'::timestamptz, 'acc_8', 'acc_15');or indirectly due to a JOIN. For example, the primary key index transfer_pkey has been scanned over 2210002 times.
- idx_tup_read
- This is the number of index entries returned as a result
of an index scan. An easy-to-understand example is the primary key
(e.g.
select * from finance.transfer where (transfer_created_at, transaction_account, counterparty_account) = ('2025-11-25 18:04:26.298329+00'::timestamptz, 'acc_8', 'acc_15');). If there is such transfer, then idx_tup_read will increase by 1. Modifying slightly the queryselect * from finance.transfer where (transfer_created_at, transaction_account, counterparty_account) in (('2025-11-25 18:04:26.298329+00'::timestamptz, 'acc_8', 'acc_15'), ('2025-11-25 01:39:36.594342+00'::timestamptz, 'acc_11', 'acc_9'));idx_tup_read will increase by 2 (if both transfers exist). In both of these queries, idx_scan will increase by 1.
- idx_tup_fetch
- These are the number of rows fetched from the table
as a result of an index scan. This is increased as a result of both
positive and false positive results. For example, if both ids exist,
the query
select * from finance.transfer where (transfer_created_at, transaction_account, counterparty_account) in (('2025-11-25 18:04:26.298329+00'::timestamptz, 'acc_8', 'acc_15'), ('2025-11-25 01:39:36.594342+00'::timestamptz, 'acc_11', 'acc_9')) and transfer_status='completed';will increase idx_tup_fetch by 2 even if only one tuple is returned to the client. The reason is that the tuples will need to be loaded from disk to examine the value of ‘transfer_status’.
OLTP
In OLTP workloads, the DBMS needs to quickly read and write individual rows of data while ensuring data integrity(Datta 2024).
Below we showcase some interesting OLTP workflows on the feature list:
- Listing with pagination
- Display details of a transfer, including the transactions that were generated
Listing
Listing should be simple enough, but it contains traps for if one uses
the naive OFFSET approach(Winand, n.d.):
- the pages drift when inserting new sales because the numbering is always done from scratch;
- the response time increases when browsing further back.
Proper pagination
In order to avoid the problems above, we need to leverage the primary
key index directly by using values instead of offsets. Given that we are
listing all transfers/transactions for a given account sorted by time,
this maps directly to the composite primary key index, allowing PostgreSQL
to do an equality match on the first two columns and then a backward
index scan from the cursor position on transfer_created_at:
select *
from finance.transfer
where routing_number = ?
and account_number = ?
and transfer_created_at < ?
order by transfer_created_at desc
fetch first 10 rows only;
Primary Key Column Order
In order to enable the listing above, the primary key definition needs to reflect the access pattern:
routing_number, account_number- identifies the account (most selective)transfer_created_at- enables efficient time-range queries on account transfers, which enables the paginationcounterparty_routing_number, counterparty_account_number- completes the transfer identity
The history of a transfer
In order to implement feature 5, we need to query the full state history of transfers intermingling it with the proper transactions. We define this as a view, since it represents a derived relation that will be reused throughout the system:
create or replace view finance.transfer_activity as
select 'transfer' as kind,
t.routing_number,
t.account_number,
t.counterparty_routing_number,
t.counterparty_account_number,
t.amount,
t.status,
t.transfer_created_at as created_at
from finance.transfer t
union all
select 'transfer_history' as kind,
h.routing_number,
h.account_number,
h.counterparty_routing_number,
h.counterparty_account_number,
h.amount,
h.status,
h.transfer_created_at as created_at
from finance.transfer_status_log h
union all
select 'pending_transaction' as kind,
pt.routing_number,
pt.account_number,
pt.counterparty_routing_number,
pt.counterparty_account_number,
pt.amount,
'pending' as status,
pt.transaction_created_at as created_at
from finance.pending_transaction pt
union all
select 'settled_transaction' as kind,
st.routing_number,
st.account_number,
st.counterparty_routing_number,
st.counterparty_account_number,
st.amount,
'settled' as status,
st.transaction_created_at as created_at
from finance.settled_transaction st;
comment on view finance.transfer_activity is
'Unified view of the full history of transfers and their associated
transactions. Each row is tagged with a kind discriminator. Used for
transfer history display and as the foundation for the updatable
interface defined in the On decoupling section.';
Querying the full history of a specific transfer is now a simple filter on the view:
select *
from finance.transfer_activity
where routing_number = ?
and account_number = ?
and counterparty_routing_number = ?
and counterparty_account_number = ?
order by created_at;
OLAP
In OLAP workloads, the DBMS needs manage large volumes of data while allowing for quick query response times(Datta 2024). Calculating account balances, which is what we need to do in order to implement requirement 4, fit squarely into that category.
As a reminder, we need to compute two balances per account, queryable at any point in time:
- Current balance
- the balance you earn interest on, derived from settled transactions only.
- Available balance
- the amount you’re able to move out, derived from both settled and pending transactions.
Obviously scanning the full transaction history and computing the sum
using a row oriented DBMS like PostgreSQL would yield correct results,
but it would certainly not be quick. Worse, as the transaction table
grows, every balance query becomes a range scan over an ever-larger set
of rows.
One solution is to maintain a balance ledger incrementally via triggers. The principle is the same one behind incremental view maintenance: the cost of keeping derived data up to date is borne by the process changing the base data, with the extra operations added to the execution plan of the original insert(White 2015). We shift work from read time to write time.
In our case, this trade-off is acceptable: transactions are append-only (no updates or deletes), and per account, we don’t expect a swarm of concurrent transactions. The write overhead of maintaining the balance ledger is small compared to the read savings of never having to aggregate the full transaction history.
Balance ledger
The finance.balance_ledger table stores a snapshot of both balances
after every transaction. Each row records the cumulative totals as of
that transaction’s timestamp, enabling queries like “what was the
balance at close of business yesterday?” via a single index-backed
lookup.
create table finance.balance_ledger (
routing_number finance.routing_number not null,
account_number finance.account_number not null,
as_of timestamptz not null,
current_total bigint not null,
available_total bigint not null,
primary key (routing_number, account_number, as_of)
);
comment on table finance.balance_ledger is
'Running balance snapshots per account. Each row records the cumulative
current and available totals as of a given transaction timestamp.
Maintained incrementally by triggers on settled and pending transaction
inserts. Current total reflects settled transactions only. Available
total reflects both settled and pending transactions.';
revoke update, delete on finance.balance_ledger from finance;
Incremental maintenance via triggers
When a settled transaction is inserted, both the current and available totals change. When a pending transaction is inserted, only the available total changes. Each trigger fetches the most recent ledger row for the account and appends a new snapshot with the updated running totals.
create or replace function finance.update_balance_on_settled()
returns trigger language plpgsql as $$
declare
v_current bigint;
v_available bigint;
begin
select current_total, available_total
into v_current, v_available
from finance.balance_ledger
where routing_number = NEW.routing_number
and account_number = NEW.account_number
order by as_of desc
limit 1;
if not found then
v_current := 0;
v_available := 0;
end if;
insert into finance.balance_ledger
(routing_number, account_number, as_of, current_total, available_total)
values
(NEW.routing_number, NEW.account_number, NEW.transaction_created_at,
v_current + NEW.amount, v_available + NEW.amount);
return NEW;
end;
$$;
create trigger settled_update_balance
after insert on finance.settled_transaction
for each row
execute function finance.update_balance_on_settled();
create or replace function finance.update_balance_on_pending()
returns trigger language plpgsql as $$
declare
v_current bigint;
v_available bigint;
begin
select current_total, available_total
into v_current, v_available
from finance.balance_ledger
where routing_number = NEW.routing_number
and account_number = NEW.account_number
order by as_of desc
limit 1;
if not found then
v_current := 0;
v_available := 0;
end if;
insert into finance.balance_ledger
(routing_number, account_number, as_of, current_total, available_total)
values
(NEW.routing_number, NEW.account_number, NEW.transaction_created_at,
v_current, v_available + NEW.amount);
return NEW;
end;
$$;
create trigger pending_update_balance
after insert on finance.pending_transaction
for each row
execute function finance.update_balance_on_pending();
With this design, querying the balance at any point in time is a simple index-backed lookup:
-- Balance as of a specific timestamp
select current_total, available_total
from finance.balance_ledger
where routing_number = ?
and account_number = ?
and as_of <= ?
order by as_of desc
fetch first 1 row only;
-- Latest balance
select current_total, available_total
from finance.balance_ledger
where routing_number = ?
and account_number = ?
order by as_of desc
fetch first 1 row only;
On serializable isolation
The constraint triggers in the constraints section and the balance
ledger triggers in the OLAP section share a common vulnerability under
PostgreSQL’s default READ COMMITTED isolation level: they all follow a
read-then-write pattern. A transaction reads some state (a transfer’s
status, a transfer’s period bounds, the latest balance row), makes a
decision based on that state, and then writes. Under READ COMMITTED,
concurrent transactions can each read a snapshot that does not reflect
the other’s uncommitted changes, and both proceed to write, producing an
inconsistent result.
Concrete examples:
-
Lost balance updates: Two concurrent inserts into
settled_transactionfor the same account both read the latestbalance_ledgerrow ascurrent_total = 1000. Both insert a new ledger row withcurrent_total = 1000 + amount, when the second should have been1000 + amount_A + amount_B. The running total is silently corrupted. -
Pending transaction against a closing transfer:
ensure_pending_transferreads the transfer asstatus = 'pending'and allows the insert. Concurrently, another transaction updates the transfer tocompleted. Both commit, and a pending transaction now references a completed transfer. -
Transaction outside transfer period:
transaction_within_transfer_periodreads the transfer period as open and allows the insert. Concurrently, the transfer’s period is being closed by a status transition. Both commit, and a transaction exists outside its transfer’s period. -
Future transaction slipping past closure:
no_future_transactions_on_closechecks for future transactions and finds none. Concurrently, another transaction inserts one. Both commit, and the transfer is closed with a transaction stranded after the closure time.
All of these are instances of the same fundamental problem: write skew
under snapshot isolation. The solution is SERIALIZABLE isolation:
alter role finance set default_transaction_isolation = 'serializable';
Under PostgreSQL’s Serializable Snapshot Isolation (SSI), the engine tracks read-write dependencies between concurrent transactions. When it detects a dependency cycle that could produce a result impossible under any serial execution, it aborts one of the transactions with a serialization failure. The application must be prepared to retry aborted transactions, but the data invariants are never violated.
This is a global setting because the problem is global: every read-then-write constraint trigger and every incremental balance update is vulnerable. Setting isolation per-transaction would require the application to know which transactions touch which tables, and a single missed annotation would silently open a consistency hole. The database default eliminates that risk.
The cost is that some transactions will be aborted and must be retried. In our case, this cost is low: the serialization conflicts occur only between concurrent writes to the same account, and per account, we don’t expect a swarm of concurrent transactions. The application can use straightforward retry logic such as exponential backoff(Brooker 2015). The alternative of risking silent data corruption is certainly not acceptable in a financial system.
On decoupling
Views are the canonical way to implement modularity in SQL DBMSes like PostgreSQL(Bellani 2024). As Codd originally envisioned, views provide logical data independence: application programs and terminal activities remain unaffected when the internal representation of data changes(Codd 1970). In non-alien language: the relation between interfaces (views) and implementations (base tables) is many-to-many, which is precisely the definition of modularity(Koppel 2023).
This means that instead of reaching for microservices to achieve decoupling — with all their attendant costs in serialization overhead, distributed consistency problems, and operational complexity(Ghemawat et al. 2023) — we can achieve the same logical property using views over a single PostgreSQL instance.
The finance.transfer_activity view defined in the history of a
transfer section already provides a stable read interface. Now we make
it updatable, turning it into the single interface through which
applications insert transfers and transactions, and update transfer
status:
create or replace function finance.transfer_activity_insert()
returns trigger language plpgsql as $$
begin
case NEW.kind
when 'transfer' then
insert into finance.transfer
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.amount);
when 'pending_transaction' then
insert into finance.pending_transaction
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
transfer_created_at, amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.created_at, NEW.amount);
when 'settled_transaction' then
insert into finance.settled_transaction
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
transfer_created_at, amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.created_at, NEW.amount);
else
raise exception 'Unknown kind: %. Must be transfer, pending_transaction, or settled_transaction', NEW.kind;
end case;
return NEW;
end;
$$;
create trigger transfer_activity_insert_trigger
instead of insert on finance.transfer_activity
for each row
execute function finance.transfer_activity_insert();
create or replace function finance.transfer_activity_update()
returns trigger language plpgsql as $$
begin
if OLD.kind <> 'transfer' then
raise exception 'Only current transfers can be updated, not %', OLD.kind;
end if;
update finance.transfer
set status = NEW.status
where routing_number = OLD.routing_number
and account_number = OLD.account_number
and transfer_created_at = OLD.created_at
and counterparty_routing_number = OLD.counterparty_routing_number
and counterparty_account_number = OLD.counterparty_account_number;
return NEW;
end;
$$;
create trigger transfer_activity_update_trigger
instead of update on finance.transfer_activity
for each row
execute function finance.transfer_activity_update();
Applications interact with finance.transfer_activity as a single
unified stream. They can:
- Read the full history of a transfer and its transactions, filtered by account and transfer identity, ordered by time.
- Insert new transfers (
kind = 'transfer'), pending transactions (kind = 'pending_transaction'), or settled transactions (kind = 'settled_transaction'). TheINSTEAD OFtrigger routes each insert to the correct underlying table, where all constraint triggers, temporal foreign keys, and balance ledger maintenance fire as usual. For transactions,created_atidentifies the originating transfer. - Update a transfer’s status by updating a row where
kind = 'transfer'. TheINSTEAD OFtrigger routes the status change tofinance.transfer, where the state machine trigger and all constraint triggers fire as usual.
If the underlying table structure changes — columns are renamed, new columns are added, tables are split or merged — the view definition is updated once, and every application continues to work unchanged.
This is decoupling achieved at the data level, with no network hops, no serialization overhead, and no distributed consistency problems. The view is the interface, and the base tables are the implementation.
Benchmarking the startup scenario
To validate the design under realistic conditions, we use pgbench with
custom scripts that exercise the full write and read paths through the
finance.transfer_activity view. The scenario models the startup tier
from the capacity planning section: 10,000 transfers per day with an
80/20 read/write split.
Seed data
First, we seed 100 managed and 100 external accounts:
-- Seed external accounts
insert into finance.external_account (routing_number, account_number, account_name)
select lpad(i::text, 9, '0'),
lpad(i::text, 12, '0'),
'External Account ' || i
from generate_series(1, 100) as i
on conflict do nothing;
-- Seed managed accounts
insert into finance.managed_active_account (routing_number, account_number, account_name)
select lpad((i + 100)::text, 9, '0'),
lpad((i + 100)::text, 12, '0'),
'Managed Account ' || i
from generate_series(1, 100) as i
on conflict do nothing;
Write script: full transfer lifecycle
Each invocation of this script exercises the complete lifecycle through
the updatable view: create a transfer, insert a pending transaction,
then complete the transfer and insert a settled transaction. Transfer
creation and the pending transaction each run in their own transaction,
mirroring how a real application would process these at different points
in time. The completion and settled transaction are grouped in a single
transaction because the state machine closes the transfer period with
now(), and the settled transaction’s transaction_created_at (which
also defaults to now()) must fall within that period. Every constraint
trigger, the state machine, the temporal foreign key, and the balance
ledger triggers all fire on each run.
\set managed_id random(1, 100)
\set external_id random(1, 100)
\set amount random(100, 100000)
-- 1. Create transfer via the view
insert into finance.transfer_activity
(kind, routing_number, account_number,
counterparty_routing_number, counterparty_account_number, amount)
values
('transfer',
lpad((:managed_id + 100)::text, 9, '0'),
lpad((:managed_id + 100)::text, 12, '0'),
lpad(:external_id::text, 9, '0'),
lpad(:external_id::text, 12, '0'),
:amount);
-- 2. Retrieve the transfer we just created
select created_at as xfer_ts
from finance.transfer_activity
where kind = 'transfer'
and routing_number = lpad((:managed_id + 100)::text, 9, '0')
and account_number = lpad((:managed_id + 100)::text, 12, '0')
and counterparty_routing_number = lpad(:external_id::text, 9, '0')
and counterparty_account_number = lpad(:external_id::text, 12, '0')
and status = 'pending'
order by created_at desc
fetch first 1 row only
\gset
-- 3. Insert pending transaction via the view (transfer is still pending)
insert into finance.transfer_activity
(kind, routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
created_at, amount)
values
('pending_transaction',
lpad((:managed_id + 100)::text, 9, '0'),
lpad((:managed_id + 100)::text, 12, '0'),
lpad(:external_id::text, 9, '0'),
lpad(:external_id::text, 12, '0'),
':xfer_ts', :amount);
-- 4. Complete the transfer and insert settled transaction atomically.
-- This ensures now() is the same for the period close and the
-- settled transaction's transaction_created_at.
begin;
update finance.transfer_activity
set status = 'completed'
where kind = 'transfer'
and routing_number = lpad((:managed_id + 100)::text, 9, '0')
and account_number = lpad((:managed_id + 100)::text, 12, '0')
and counterparty_routing_number = lpad(:external_id::text, 9, '0')
and counterparty_account_number = lpad(:external_id::text, 12, '0')
and created_at = ':xfer_ts';
insert into finance.transfer_activity
(kind, routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
created_at, amount)
values
('settled_transaction',
lpad((:managed_id + 100)::text, 9, '0'),
lpad((:managed_id + 100)::text, 12, '0'),
lpad(:external_id::text, 9, '0'),
lpad(:external_id::text, 12, '0'),
':xfer_ts', :amount);
commit;
Read script: activity stream and balance
Each invocation queries the transfer activity stream for a random account (paginated) and its latest balance:
\set managed_id random(1, 100)
-- Read transfer activity stream (latest 20 entries)
select *
from finance.transfer_activity
where routing_number = lpad((:managed_id + 100)::text, 9, '0')
and account_number = lpad((:managed_id + 100)::text, 12, '0')
order by created_at desc
fetch first 20 rows only;
-- Read latest balance
select current_total, available_total
from finance.balance_ledger
where routing_number = lpad((:managed_id + 100)::text, 9, '0')
and account_number = lpad((:managed_id + 100)::text, 12, '0')
order by as_of desc
fetch first 1 row only;
Running the benchmark
# 1. Apply the full schema (Appendix A)
psql -f only_postgres_code.sql
# 2. Seed accounts
psql -f pgbench_setup.sql
# 3. Run 80/20 read/write mix for 60 seconds
# @4 = weight 4 (80%), @1 = weight 1 (20%)
# -c 10: 10 concurrent clients
# -j 4: 4 worker threads
# -P 5: progress every 5 seconds
# -T 60: run for 60 seconds
pgbench -h localhost -p 54321 -U admin -d blog \
--no-vacuum \
-f pgbench_read.sql@4 \
-f pgbench_write.sql@1 \
-c 10 -j 4 -T 60 -P 5
Results
pgbench (18.4)
transaction type: multiple scripts
scaling factor: 1
query mode: simple
number of clients: 10
number of threads: 4
maximum number of tries: 1
duration: 60 s
number of transactions actually processed: 45985
number of failed transactions: 0 (0.000%)
latency average = 13.044 ms
latency stddev = 12.449 ms
initial connection time = 17.840 ms
tps = 766.151693 (without initial connection time)
SQL script 1: pgbench_read.sql
- weight: 4 (targets 80.0% of total)
- 36793 transactions (80.0% of total)
- latency average = 8.080 ms
- latency stddev = 6.135 ms
SQL script 2: pgbench_write.sql
- weight: 1 (targets 20.0% of total)
- 9191 transactions (20.0% of total)
- latency average = 32.915 ms
- latency stddev = 11.455 ms
Key takeaways:
- 766 TPS overall with 0 failed transactions. The startup target of 10,000 transfers/day is ~0.12 TPS. We exceed that by over 6,000x, confirming massive headroom on modest hardware.
- 0 serialization failures: Despite 10 concurrent clients writing to
100 accounts under
SERIALIZABLEisolation, no transactions were aborted. The working set is distributed across enough accounts that write contention is negligible at this scale. - 8ms average read latency: The
UNION ALLview over 4 tables plus the balance ledger lookup completes well within interactive response time, even as the tables grow throughout the 60-second run. - 33ms average write latency: Each write transaction exercises the full constraint set that implements complex business logic (audit trails, time constraints, balances, etc) all within 33ms. This is the true cost of enforcing every business rule at the data level, and it is more than acceptable.
These results were obtained on a development laptop, not production hardware. On an RDS instance sized for the working set (as described in the capacity planning section), performance would be significantly better.
Conclusion
We set out to show that the default assumption for your data problems should be that your company can do fine with just PostgreSQL. Let’s revisit each objection from the setup and see how it was addressed:
- I’ll need auditing and reconstructing state
- System-time temporal tables (transfer state history) give you a complete, automatic audit trail of every transfer status transition. No event store, no append-only log infrastructure — just a history table maintained by a trigger.
- Write throughput is too low
- By keeping the working set (2 days
of transfers and transactions) sized to fit in
shared_buffers, and by aligning indexes with immutable columns to enable HOT updates that eliminate write amplification on transfer status transitions, we maximize write performance without any external caching layer. - The transactional queries are too slow
- Keyset pagination over
composite primary keys, as shown in the OLTP section, gives stable,
index-backed listing performance that doesn’t degrade as you page
deeper. Transfer history queries are a single
UNION ALLover indexed tables. - The analytical queries are too slow
- The balance ledger maintains running balance snapshots incrementally via triggers, turning what would be a full-table aggregation into a single index-backed lookup at any point in time.
- My app will be coupled to the Database
- The updatable view
finance.transfer_activityserves as a stable interface for reading activity, inserting transfers and transactions, and updating transfer status through a single unified stream. If the underlying tables change, the view definition is updated once and every application continues to work unchanged. This is modularity achieved at the data level(Bellani 2024), with no network hops, no serialization overhead, and no distributed consistency problems(Ghemawat et al. 2023).
All of this runs on a single vanilla PostgreSQL 18 instance with standard extensions available on RDS. No distributed-systems cosplay, no infrastructure proliferation, no operational complexity tax. We have only scratched the surface of what is available both in PostgreSQL as a SQL engine and in relational theory properly understood.

Figure 3: 1936 fire in the Sagrada Familia, set by communist revolutionaries
Appendix A: Full code suite.
create schema finance;
create role finance;
grant usage on schema finance to finance;
alter default privileges in schema finance
grant select, insert, update, delete on tables to finance;
alter default privileges in schema finance
grant usage, select on sequences to finance;
create domain finance.routing_number as text
check (value ~ '^[0-9]{9}$');
create domain finance.account_number as text
check (value ~ '^[0-9]{12}$');
create domain finance.transfer_status as text
check(value in ('pending',
'returned',
'completed'));
-- To use temporal constraints, you need to install the btree_gist extension, which provides the necessary operator classes for creating GiST indexes on scalar data types:
create extension if not exists btree_gist;
create table finance.managed_active_account(
routing_number finance.routing_number not null,
account_number finance.account_number not null,
account_name text not null,
account_active_period tstzrange not null default tstzrange(now(), 'infinity', '[)'),
primary key (routing_number,
account_number,
account_active_period without overlaps)
);
comment on table finance.managed_active_account is
'Managed Accounts are what transactions are performed against. Think of your bank account. They store money, receive transfers, and send payments. They earn interest and have depository insurance. This relation holds the accounts that are active. No transfer may be created for accounts in the period that they were inactive.';
create table finance.external_account(
routing_number finance.routing_number not null,
account_number finance.account_number not null,
account_name text not null,
primary key (routing_number, account_number)
);
comment on table finance.external_account is
'External accounts represent counterparty accounts at other institutions. They are the other side of a transfer. Unlike managed accounts, they have no temporal active period since we do not control their lifecycle.';
-- Ensure managed and external accounts never share the same identity
create or replace function finance.not_external_account(
p_routing_number finance.routing_number,
p_account_number finance.account_number
)
returns boolean language sql stable as $$
select not exists (
select 1
from finance.external_account
where routing_number = p_routing_number
and account_number = p_account_number
);
$$;
create or replace function finance.not_managed_account(
p_routing_number finance.routing_number,
p_account_number finance.account_number
)
returns boolean language sql stable as $$
select not exists (
select 1
from finance.managed_active_account
where routing_number = p_routing_number
and account_number = p_account_number
);
$$;
alter table finance.managed_active_account
add constraint managed_not_external
check (finance.not_external_account(routing_number, account_number));
alter table finance.external_account
add constraint external_not_managed
check (finance.not_managed_account(routing_number, account_number));
create table finance.transfer (
transfer_period tstzrange not null default tstzrange(now(), 'infinity', '[)'),
transfer_created_at timestamptz
generated always as (lower(transfer_period)) stored,
account_number finance.account_number not null,
routing_number finance.routing_number not null,
counterparty_account_number finance.account_number not null,
counterparty_routing_number finance.routing_number not null,
amount bigint not null,
status finance.transfer_status not null default 'pending',
-- Natural order: account identity, then time, then counterparty
-- This enables efficient time-range queries on account transfers
primary key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
),
foreign key (
counterparty_routing_number,
counterparty_account_number
) references finance.external_account (
routing_number,
account_number
),
-- temporal foreign key: ensure managed account exists during transfer period
foreign key (
routing_number,
account_number,
period transfer_period
) references finance.managed_active_account (
routing_number,
account_number,
period account_active_period
)
);
comment on table finance.transfer is
'Transfers represent money movement between an external account and a managed account. Status follows state machine: pending -> (completed | returned). Period closes on terminal state. transfer_created_at is a stored generated column derived from lower(transfer_period), eliminating redundancy while remaining usable in primary keys and foreign key references.';
revoke insert on finance.transfer from finance;
revoke update on finance.transfer from finance;
-- transfer_period will be managed based on the status
grant insert (routing_number,
account_number,
counterparty_routing_number,
counterparty_account_number,
amount) on finance.transfer to finance;
grant update (status) on finance.transfer to finance;
-- Add system-time period column to transfer table
alter table finance.transfer add column if not exists sys_period tstzrange default tstzrange(current_timestamp, null);
alter table finance.transfer alter column sys_period set not null;
-- Focused history table - only what we need for status transitions
create table if not exists finance.transfer_status_log (
like finance.transfer
);
comment on table finance.transfer_status_log is
'Automatic log of all transfer status transitions via temporal_tables extension. Shows complete state machine history.';
alter table finance.transfer_status_log
add primary key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number,
sys_period
);
-- Use temporal_tables versioning procedure
create trigger transfer_save_status_history
before insert or update or delete
on finance.transfer
for each row
execute procedure versioning('sys_period', 'finance.transfer_status_log', true);
-- Add system-time period column to the account table
alter table finance.managed_active_account add column if not exists sys_period tstzrange default tstzrange(current_timestamp, null);
alter table finance.managed_active_account alter column sys_period set not null;
create table if not exists finance.managed_active_account_log (
like finance.managed_active_account
);
comment on table finance.managed_active_account_log is
'Automatic log of all account activity via temporal_tables extension.';
create index on finance.managed_active_account_log (sys_period);
create index on finance.managed_active_account_log (routing_number, account_number);
-- Use temporal_tables versioning procedure
create trigger account_save_history
before insert or update or delete
on finance.managed_active_account
for each row
execute procedure versioning('sys_period', 'finance.managed_active_account_log', true);
create table finance.settled_transaction (
transaction_created_at timestamptz not null default now(),
account_number finance.account_number not null,
routing_number finance.routing_number not null,
counterparty_account_number finance.account_number not null,
counterparty_routing_number finance.routing_number not null,
transfer_created_at timestamptz not null,
amount bigint not null,
primary key (
account_number,
routing_number,
transaction_created_at
),
foreign key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
references finance.transfer (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
);
comment on table finance.settled_transaction is
'Settled transactions affect both your available balance and your current balance. They are immutable events --- no updates or deletes permitted.';
revoke update, delete on finance.settled_transaction from finance;
create table finance.pending_transaction (
like finance.settled_transaction including all,
foreign key (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
references finance.transfer (
routing_number,
account_number,
transfer_created_at,
counterparty_routing_number,
counterparty_account_number
)
);
comment on table finance.pending_transaction is
'Pending transactions represent potential future credits or debits. They affect available balance but not current balance. Immutable once created.';
revoke update, delete on finance.pending_transaction from finance;
create or replace function finance.enforce_transfer_state_machine()
returns trigger language plpgsql as $$
begin
if OLD.status = NEW.status then
return NEW;
end if;
if OLD.status = 'pending' then
if NEW.status not in ('completed', 'returned') then
raise exception 'Invalid state transition: pending can only transition to completed or returned, not %', NEW.status;
end if;
NEW.transfer_period := tstzrange(lower(OLD.transfer_period), now(), '[]');
elsif OLD.status in ('completed', 'returned') then
raise exception 'Invalid state transition: % is a terminal state and cannot transition to %', OLD.status, NEW.status;
end if;
return NEW;
end;
$$;
create trigger transfer_z_enforce_state_machine
before update of status on finance.transfer
for each row
when (OLD.status <> NEW.status)
execute function finance.enforce_transfer_state_machine();
create or replace function finance.transaction_within_transfer_period()
returns trigger language plpgsql as $$
declare
v_transfer_period tstzrange;
begin
select transfer_period into v_transfer_period
from finance.transfer
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number;
if not found then
raise exception 'Transfer not found for transaction';
end if;
if not (v_transfer_period @> NEW.transaction_created_at) then
raise exception
'Transaction created_at % is outside transfer period %',
NEW.transaction_created_at, v_transfer_period;
end if;
return NEW;
end;
$$;
create constraint trigger settled_transaction_within_transfer_period
after insert on finance.settled_transaction
deferrable initially deferred
for each row
execute function finance.transaction_within_transfer_period();
create constraint trigger pending_transaction_within_transfer_period
after insert on finance.pending_transaction
deferrable initially deferred
for each row
execute function finance.transaction_within_transfer_period();
create or replace function finance.is_pending_transfer(
p_routing_number finance.routing_number,
p_account_number finance.account_number,
p_transfer_created_at timestamptz,
p_counterparty_routing_number finance.routing_number,
p_counterparty_account_number finance.account_number
)
returns boolean language sql stable as $$
select exists (
select 1
from finance.transfer t
where t.routing_number = p_routing_number
and t.account_number = p_account_number
and t.transfer_created_at = p_transfer_created_at
and t.counterparty_routing_number = p_counterparty_routing_number
and t.counterparty_account_number = p_counterparty_account_number
and t.status = 'pending'
);
$$;
create or replace function finance.ensure_pending_transfer()
returns trigger language plpgsql as $$
begin
if not finance.is_pending_transfer(
NEW.routing_number,
NEW.account_number,
NEW.transfer_created_at,
NEW.counterparty_routing_number,
NEW.counterparty_account_number
) then
raise exception
'Must reference a pending transfer (%, %, %, %, %)',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at,
NEW.counterparty_routing_number, NEW.counterparty_account_number;
end if;
return NEW;
end;
$$;
create or replace function finance.ensure_non_pending_transfer()
returns trigger language plpgsql as $$
begin
if finance.is_pending_transfer(
NEW.routing_number,
NEW.account_number,
NEW.transfer_created_at,
NEW.counterparty_routing_number,
NEW.counterparty_account_number
) then
raise exception
'Cannot reference a pending transfer (%, %, %, %, %)',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at,
NEW.counterparty_routing_number, NEW.counterparty_account_number;
end if;
return NEW;
end;
$$;
create constraint trigger pending_transaction_requires_pending_transfer
after insert on finance.pending_transaction
deferrable initially deferred
for each row
execute function finance.ensure_pending_transfer();
create constraint trigger settled_transaction_requires_non_pending_transfer
after insert on finance.settled_transaction
deferrable initially deferred
for each row
execute function finance.ensure_non_pending_transfer();
create or replace function finance.no_future_transactions_on_close()
returns trigger language plpgsql as $$
begin
if exists (
select 1 from finance.settled_transaction
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number
and transaction_created_at > now()
union all
select 1 from finance.pending_transaction
where routing_number = NEW.routing_number
and account_number = NEW.account_number
and transfer_created_at = NEW.transfer_created_at
and counterparty_routing_number = NEW.counterparty_routing_number
and counterparty_account_number = NEW.counterparty_account_number
and transaction_created_at > now()
) then
raise exception
'Cannot close transfer (%, %, %): transaction(s) exist after current time',
NEW.routing_number, NEW.account_number, NEW.transfer_created_at;
end if;
return NEW;
end;
$$;
create constraint trigger transfer_no_future_transactions_on_close
after update of status on finance.transfer
deferrable initially deferred
for each row
when (NEW.status in ('completed', 'returned'))
execute function finance.no_future_transactions_on_close();
create or replace view finance.transfer_activity as
select 'transfer' as kind,
t.routing_number,
t.account_number,
t.counterparty_routing_number,
t.counterparty_account_number,
t.amount,
t.status,
t.transfer_created_at as created_at
from finance.transfer t
union all
select 'transfer_history' as kind,
h.routing_number,
h.account_number,
h.counterparty_routing_number,
h.counterparty_account_number,
h.amount,
h.status,
h.transfer_created_at as created_at
from finance.transfer_status_log h
union all
select 'pending_transaction' as kind,
pt.routing_number,
pt.account_number,
pt.counterparty_routing_number,
pt.counterparty_account_number,
pt.amount,
'pending' as status,
pt.transaction_created_at as created_at
from finance.pending_transaction pt
union all
select 'settled_transaction' as kind,
st.routing_number,
st.account_number,
st.counterparty_routing_number,
st.counterparty_account_number,
st.amount,
'settled' as status,
st.transaction_created_at as created_at
from finance.settled_transaction st;
comment on view finance.transfer_activity is
'Unified view of the full history of transfers and their associated
transactions. Each row is tagged with a kind discriminator. Used for
transfer history display and as the foundation for the updatable
interface defined in the On decoupling section.';
create table finance.balance_ledger (
routing_number finance.routing_number not null,
account_number finance.account_number not null,
as_of timestamptz not null,
current_total bigint not null,
available_total bigint not null,
primary key (routing_number, account_number, as_of)
);
comment on table finance.balance_ledger is
'Running balance snapshots per account. Each row records the cumulative
current and available totals as of a given transaction timestamp.
Maintained incrementally by triggers on settled and pending transaction
inserts. Current total reflects settled transactions only. Available
total reflects both settled and pending transactions.';
revoke update, delete on finance.balance_ledger from finance;
create or replace function finance.update_balance_on_settled()
returns trigger language plpgsql as $$
declare
v_current bigint;
v_available bigint;
begin
select current_total, available_total
into v_current, v_available
from finance.balance_ledger
where routing_number = NEW.routing_number
and account_number = NEW.account_number
order by as_of desc
limit 1;
if not found then
v_current := 0;
v_available := 0;
end if;
insert into finance.balance_ledger
(routing_number, account_number, as_of, current_total, available_total)
values
(NEW.routing_number, NEW.account_number, NEW.transaction_created_at,
v_current + NEW.amount, v_available + NEW.amount);
return NEW;
end;
$$;
create trigger settled_update_balance
after insert on finance.settled_transaction
for each row
execute function finance.update_balance_on_settled();
create or replace function finance.update_balance_on_pending()
returns trigger language plpgsql as $$
declare
v_current bigint;
v_available bigint;
begin
select current_total, available_total
into v_current, v_available
from finance.balance_ledger
where routing_number = NEW.routing_number
and account_number = NEW.account_number
order by as_of desc
limit 1;
if not found then
v_current := 0;
v_available := 0;
end if;
insert into finance.balance_ledger
(routing_number, account_number, as_of, current_total, available_total)
values
(NEW.routing_number, NEW.account_number, NEW.transaction_created_at,
v_current, v_available + NEW.amount);
return NEW;
end;
$$;
create trigger pending_update_balance
after insert on finance.pending_transaction
for each row
execute function finance.update_balance_on_pending();
alter role finance set default_transaction_isolation = 'serializable';
create or replace function finance.transfer_activity_insert()
returns trigger language plpgsql as $$
begin
case NEW.kind
when 'transfer' then
insert into finance.transfer
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.amount);
when 'pending_transaction' then
insert into finance.pending_transaction
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
transfer_created_at, amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.created_at, NEW.amount);
when 'settled_transaction' then
insert into finance.settled_transaction
(routing_number, account_number,
counterparty_routing_number, counterparty_account_number,
transfer_created_at, amount)
values
(NEW.routing_number, NEW.account_number,
NEW.counterparty_routing_number, NEW.counterparty_account_number,
NEW.created_at, NEW.amount);
else
raise exception 'Unknown kind: %. Must be transfer, pending_transaction, or settled_transaction', NEW.kind;
end case;
return NEW;
end;
$$;
create trigger transfer_activity_insert_trigger
instead of insert on finance.transfer_activity
for each row
execute function finance.transfer_activity_insert();
create or replace function finance.transfer_activity_update()
returns trigger language plpgsql as $$
begin
if OLD.kind <> 'transfer' then
raise exception 'Only current transfers can be updated, not %', OLD.kind;
end if;
update finance.transfer
set status = NEW.status
where routing_number = OLD.routing_number
and account_number = OLD.account_number
and transfer_created_at = OLD.created_at
and counterparty_routing_number = OLD.counterparty_routing_number
and counterparty_account_number = OLD.counterparty_account_number;
return NEW;
end;
$$;
create trigger transfer_activity_update_trigger
instead of update on finance.transfer_activity
for each row
execute function finance.transfer_activity_update();
References
-
Complexity here is defined as the quantity of interacting parts of a whole ↩︎
-
A note on the code snippets: we will show code as we progress on the article, but the full code suite can be found on the [BROKEN LINK: blog/all-you-need-is-postgresql.pre-processed.org::#appendix-a-full-code-suite] for ease of copy. ↩︎
-
On oracle there are further complications. See (Albe 2026) ↩︎
-
For a refresh on what these kinds of balances are, see [BROKEN LINK: blog/all-you-need-is-postgresql.pre-processed.org::#the-setup] ↩︎
-
(which is the case for Postgres(The PostgreSQL Global Development Group 2026) but not for Oracle(Oracle Corporation 2026)) ↩︎
-
Such constraints are almost never created at the data level, exposing applications to the risk of failing audits and worse. ↩︎
-
Temporal tables can be used for several interesting features:
↩︎- Auditing all data changes and performing data forensics when necessary
- Reconstructing state of the data as of any time in the past
- Calculating trends over time
- Maintaining a slowly changing dimension for decision support applications
- Recovering from accidental data changes and application errors Auditing all data changes and performing data forensics when necessary (Microsoft 2024)